This is the forth blog of a series of posts about the topics
Continuous Integration and Continuous Delivery. It explains how important continuous integration is to deliver software in short iterations to the customer with a high quality standard.
In my previous post I was explaining what role a CI build plays in the development process. Also Gated Check-in's are really important to ensure a certain code quality. But this quality highly depends on the checks and tests which are running during the CI build.
Writing unit tests and integrating them into the continuous integration build is essentially for writing code with good quality. Always assume that your code is not working until you have proven that it works by a unit test.
Software has to be permanently adapted and changed due to new requirements. That is the nature of software development because humans cannot overview the complexity of IT systems. That is also the reason why iterative and agile development processes are so successful compared to traditional waterfall and V-models.
But how to write good unit tests?
I have seen a couple of projects with totally different ideas and solutions how they created and organized their unit tests. One main goal and very important technique for writing successful unit tests is to keep the scope for a test very small. In other words just test a single class or even better a single method per test. What sounds pretty easy in theory can be challenging in the practice. Introducing unit tests in existing projects which have already a net of references can be very tricky. A good practice is to improve the code step by step. Every check-in has to make the code better. When you start a new project it is much easier to introduce good unit tests with a little effort and discipline. Patterns like inversion of control and dependency injection are techniques to reduce the dependencies between components without introducing more complexity. Do not try to write unit tests which test all your layers at once. This results in high effort for building and maintaining the test data and unit tests during the software lifecycle. Better introduce local unit tests step by step.
Here is a list of simplified best practices which can be applied in most of the cases to reach easily a looser coupling and therefore a better testability:
1. Every time you want to call another class add the interface of the class in the constructor of your class and store it as a field or property and call the interface instead of the class directly. If the class you want to call does not have an interface, what stops you from creating one? Tools like Visual Studio and ReSharper even support you doing that easily. If it is external code
just create a wrapper around this code which is anyhow a good practice to integrate external code in your application.
Assuming you want to test your business logic OrderManagement but unfortunately your business logic calls a web service through your OrderServiceProxy class. That makes testing your business logic much more difficult because every time the web service is not accessible your unit test would fail. We just add a new interface IOrderServiceProxy and add a constructor taking this interface in the Order Management class.
public class OrderManagement : IOrderManagement
{
private IOrderServiceProxy OrderService { get; set; }
public OrderManagement(IOrderServiceProxy orderService)
{
OrderService = orderService;
}
public bool ProcessOrder(Order order)
{
return OrderService.PlaceOrder(order);
}
}
2. Now you can easily test your OrderManagement class und ProcessOrder method because you can pass a replacement for the OrderServiceProxy implementation and test against your dummy implementation.
public class OrderServiceProxyMock : IOrderServiceProxy
{
public bool PlaceOrder(Order order)
{
return true;
}
}
[TestClass()]
public class OrderManagementTest
{
[TestMethod()]
public void ProcessOrderTest()
{
// Create mock class
IOrderServiceProxy orderService = new OrderServiceProxyMock();
// Create test data
Order order = new Order();
// Create your class to test and pass your external references
OrderManagement target = new OrderManagement(orderService);
// Execute your test method
var result = target.ProcessOrder(order);
// Assertions
Assert.IsTrue(result);
}
}
3. You can use a mocking framework like RhinoMock, Typemock, Justmock, NMock, etc... to simplify testing your code and reduce the lines of code you have to write.
RhineMocks example:
[TestClass()]
public class OrderManagementRhinoMocksTest
{
[TestMethod()]
public void ProcessOrderTest()
{
// Create test data
Order order = new Order();
// Create mock
MockRepository mock = new MockRepository();
IOrderServiceProxy orderService = mock.StrictMock<IOrderServiceProxy>();
orderService.Stub(x => x.PlaceOrder(order)).Return(true);
mock.ReplayAll();
// Create your class to test and pass your external references
OrderManagement target = new OrderManagement(orderService);
// Execute your test method
var result = target.ProcessOrder(order);
// Assertions
Assert.IsTrue(result);
}
}
4. You can use Dependency Injection Frameworks in order to inject the implementations in the constructors. Especially for your productive code you have in most of the cases just one implementation for an interface which can be easily mapped. There are a lot of Dependency Injection Frameworks available like Unity, StructureMap, Spring.NET, etc...
A dependency injection framework resolves the interfaces you placed in a constructor or property with the real implementation. Which interface maps to which implementation can be either configured in a xml file or just coded.
Unity Configuration example:
First you usually define your alias which maps to a full qualified type name. You have to do that for your interface as well as your implementation. After that you can register a mapping from the interface to the actual implementation.
<configuration>
<configSections>
<section name="unity" type="Microsoft.Practices.Unity.Configuration.UnityConfigurationSection, Microsoft.Practices.Unity.Configuration" />
</configSections>
<unity xmlns="http://schemas.microsoft.com/practices/2010/unity">
<alias alias="IOrderServiceProxy" type="TSTune.CodeExamples.ServiceAgents.IOrderServiceProxy, TSTune.CodeExamples" />
<alias alias="OrderServiceProxy" type="TSTune.CodeExamples.ServiceAgents.OrderServiceProxy, TSTune.CodeExamples" />
<alias alias="IOrderManagement" type="TSTune.CodeExamples.BusinessLogic.IOrderManagement, TSTune.CodeExamples" />
<alias alias="OrderManagement" type="TSTune.CodeExamples.BusinessLogic.OrderManagement, TSTune.CodeExamples" />
<container>
<register type="IOrderServiceProxy" mapTo="OrderServiceProxy"/>
<register type="IOrderManagement" mapTo="OrderManagement"/>
</container>
</unity>
</configuration>
After you configured your unity container you have to load the configuration and initialize your unity container before you can use it:
IUnityContainer unityContainer = new UnityContainer();
UnityConfigurationSection section = (UnityConfigurationSection)ConfigurationManager.GetSection("unity");
section.Configure(container);
Unity Code example:
You can also register the mappings using code, which is much easier:
IUnityContainer container = new UnityContainer();
container.RegisterType<IOrderManagement, OrderManagement>();
container.RegisterType<IOrderServiceProxy, OrderServiceProxy>();
But this approach has two disadvantages:
First of all you have to recompile your code to exchange implementations. Secondly a static reference has to be added to all the assemblies you want to register, because the classes have to be known during registration. This can be problematic when you use the Visual Studio Layer Diagram Validation, which I am going to explain in one of my next posts.
Unity - How to use it:
Every time you call now UnityContainer.Resolve<IOrderManagement>(); you will get an instance of your OrderManagement class.
var orderManagement = unityContainer.Resolve<IOrderManagement>();
orderManagement.ProcessOrder(new Order());
5. If using a Dependency Injection Framework is too much of a pain for you (which it should not!), then you can add a default constructor which wires up all implementations with the interfaces. This is called poor man's dependency injection.
public OrderManagement()
{
OrderService = new OrderServiceProxy();
}
If you are using interfaces instead of real implementations you lose the chance to easily navigate with F12 through your code during design time. Instead you end up looking at the interface
when you want to investigate the implementation and you have to search the actual implementation manually. ReSharper helps you navigating directly to the implementation by clicking Ctrl+F12.
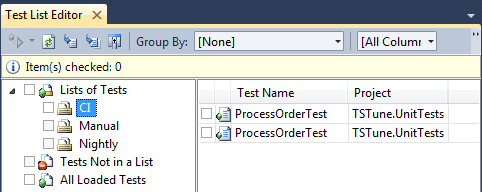
How to integrate in the Team Foundation Server Build:
First, you should create your test lists. Usually there is a test list for CI, Nightly and maybe Manual tests.
After you placed your unit tests in the test lists, you can set up the TFS build to execute your test list in the CI build. Do not forget to fail the build if the test execution failed.
Final important note !!!
Think about unit test code like productive code. Use the same quality criteria. Unit test code has to be maintained together with your productive code and underlies the same changes!
This makes writing and maintaining of your unit test code much easier and increases the quality of your code.